什么是ByteBuf
数据在网络上是以字节流的形式进行传输的。Java官方的NIO提供了一个ByteBuffer类作为字节的容器。但是ByteBuffer的使用比较复杂,尤其是需要通过flip()方法对读写进行切换。因此netty重新设计了一个字节容器,即ByteBuf,没有了ByteBuf,Netty就失去了灵魂,其他所有的都将变得毫无意义。
ByteBuf与ByteBuffer的对比
Netty的ByteBuf采用了读写索引分离的策略(readerIndex与writerIndex),一个初始化(里面尚未有任何数据)的ByteBuf的readerIndex与writerIndex值都为0;
当读索引与写索引处于同一个位置时,如果继续读取,那么就会抛出IndexOutOfBoundsException;
对于ByteBuf的任何读写操作都会分别单独维护读索引与写索引。maxCapacity最大容量默认的限制时Integer.MAX_VALUE;
存储字节的数组时动态的,其最大值默认是Integer.MAX_VALUE。这里的动态性时体现在write方法中的,write方法在执行时会判断buffer容量,如果不足则自动扩容;
ByteBuf的读写索引是完全分开的,使用起来更加方便;
一旦分配好之后不能动态扩容与收缩;而且当待存储的数据字节很大时就很有可能出现IndexOutOfBoundsException。如果要预防这个异常,那就需要在存储之前完全确定好待存储的字节大小。如果ByteBuffer的空间不足,我们只有一种解决方案:创建一个全新的ByteBuffer对象,然后再将之前的ByteBuffer的数据复制过去,这一切操作都需要由开发者自己来手动完成;
ByteBuffer只使用一个position指针来标识位置信息,在进行读写切换时就需要调用flip方法或是rewind方法,使用起来很不方便;
ByteBuf的结构
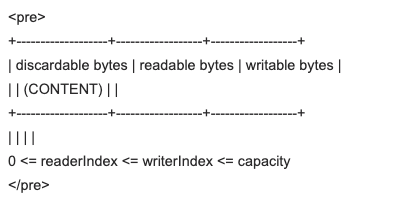
discardable bytes
表示已经被读过的字节,可以被丢弃了,当前readerIndex已经到达了被丢弃字节的索引位置,0~readerIndex的就被视为discard的,调用discardReadBytes方法,可以释放这部分空间,它的作用类似ByteBuffer的compact方法,将字节往前移动,readerIndex设置为0,writerIndex设置为oldWriterIndex - oldReaderIndex;
readable bytes
表示还没有被读过的字节,是当前ByteBuf对象中保存的内容。需要注意的是,如果可读字节数已经耗尽了,这时再次尝试从ByteBuf中读取内容的话,将会抛出IndexOutOfBoundsException的异常,所以在读数据之前最好先通过byteBuf.isReadable()判断一下;
writable bytes
表示当前ByteBuf对象中剩余可写的字节空间,当writerIndex移动到capacity-1的位置时,就不可再写了,ByteBuf默认的最大容量是Integer.MAX_VALUE。如果没有更多的可写空间了,但是仍然还在往ByteBuf中写数据的话,会抛出IndexOutOfBoundsException的异常,所以在往ByteBuf中写数据之前最好先通过byteBuf.isWriteable()判断一下;
ByteBuf的扩容原理
|
|
首先设置门限阈值为4M,当需要的新容量正好等于门限阈值时,使用阈值作为新的缓冲区容量。如果新申请的内存空间大于阈值,不能采用倍增的方式(防止内存膨胀和浪费)扩张内存,而采用每次倍增4M的方式进行内存扩张。扩张的时候需要对扩张后的内存和最大内存(maxCapacity)进行比较,如果大于缓冲区的最大长度,则使用maxCapacity作为扩容后的缓冲区容量。如果扩容后的新容量小于阈值,则以64为计数进行倍增,直到倍增后的结果大于或等于需要的容量值。
分析原因:
采用倍增或者步进算法的原因如下:如果以minNewCapacity作为目标容量,则本次扩容后的可写字节数刚好够本次写入使用。写入完成后,它的可写字节数会变为0,下次做写入操作的时候需要做动态扩张。这样就会形成第一次动态扩张,每次写入操作都会进行动态扩张,由于动态扩张需要进行内存复制,频繁的内存复制会导致性能下降。
采用先倍增后步进的原因如下:当内存比较小的情况下,倍增操作并不会带来太多的内存浪费,例如64字节–>128字节–>256字节,这样的内存扩张方式对于大多数应用系统是可以接受的。但是,当内存增长到一定阈值后,在进行倍增就会带来额外的内存浪费,例如10MB,采用倍增后变为20MB。但很有可能系统只需要12MB,则扩张到20M会带来8MB的内存浪费。由于每个客户端连接都可能维护自己独立的接收和发送缓冲区,这样随着客户读的线性增长,内存浪费也会成比例地增加,因此,达到某个阈值后就需要以步进的方式对内存进行平滑的扩张。
这个阈值是个经验值,不同的应用场景,这个值可能不同,此处,ByteBuf取值为4MB。
重新计算完动态扩张后的目标容量后,需要重新创建个新的缓冲区,将原缓冲区的内容复制到新创建的ByteBuf中,最后设置读写索引和mark标签等。由于不同的子类会对应不同的复制操作,所以该方法依然是个抽象方法,由子类负责实现。
ByteBuf的相关子类
从内存分配的角度看,ByteBuf 可以分为两类:
堆内存字节缓冲区 HeapByteBuf:优点是内存分配和回收速度快,可以被 JVM 自动回收。缺点是,如果进行 Socket 的 I/O 读写,需要额外做一次内存复制,在堆内存缓冲区和内核 Channel 之间进行复制,性能会有一定程度下降。
直接内存字节缓冲区 DirectByteBuf:非堆内存,直接在堆外进行分配。相比于堆内存,内存分配和回收稍慢,但是可以减少复制,提升性能。
两种内存,各有利弊。Netty 最佳实践表明:在 I/O 通信线程的读写缓冲区使用 DirectByteBuf,后端业务消息的编解码模块使用 HeapByteBuf,这样组合可以达到性能最优。
从内存回收的角度看,ByteBuf 也分为两类:基于对象池的 ByteBuf 和普通 ByteBuf。两者区别在于基于对象池的 ByteBuf 可以重用 ByteBuf 对象,它自己维护了一个内存池,可以循环利用创建的 ByteBuf,提升内存的使用效率,降低由于高负载导致的频繁 GC。内存池的缺点是管理和维护比较复杂,使用时需要更加谨慎。
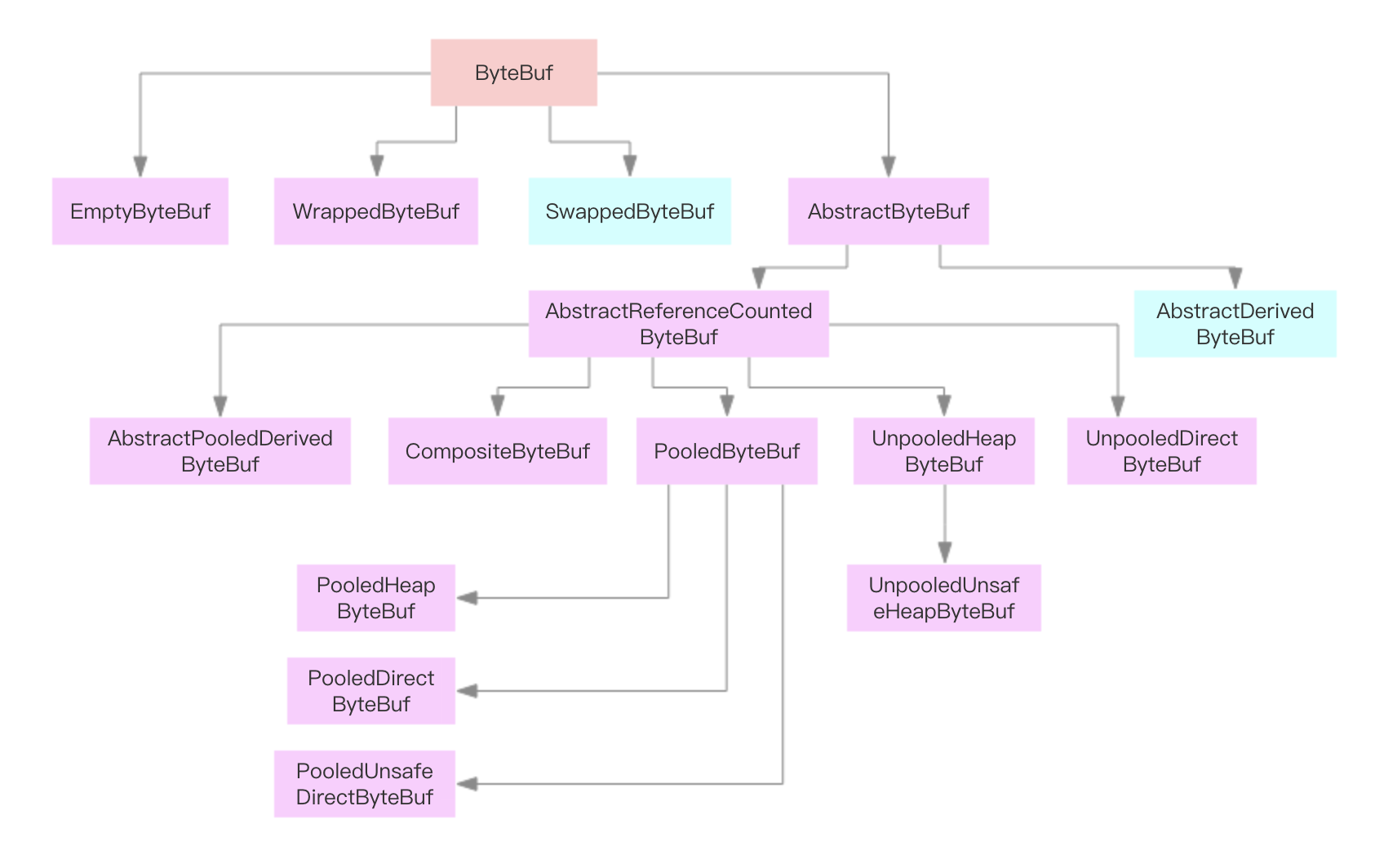
由上图我们发现:
ByteBuf有3个主要的子类:EmptyByteBuf,WrappedByteBuf,AbstractByteBuf;其中比较常用的是AbstractByteBuf,而AbstractByteBuf类又有一个子类AbstractReferenceCountedByteBuf,该类主要是实现了引用计数,然后AbstractReferenceCountedByteBuf又有很多的子类。下面我们对一些关键类进行分析和解读。
CompositeByteBuf
CompositeByteBuf允许将多个ByteBuf的实例组装到一起,形成一个统一的视图,有点类似于数据库将多个表的字段组装到一起统一用视图展示。假设我们有一份协议数据, 它由头部和消息体组成, 而头部和消息体是分别存放在两个 ByteBuf 中的当需要对消息进行编码的时候需要进行整合,如果使用JDK的默认能力,有以下2种方式:1)将某个BygeBuffer复制到另一个ByteBuffer中,或者创建一个新的ByteBuffer,将2者复制到新建的ByteBuffer中; 2)通过List或数组等容器,将消息头和消息体放到容器中进行统一维护和处理;上面的做法非常别扭,实际上遇到的问题跟数据库中视图解决的问题一致——缓冲区有多个,但是需要统一展示和处理,必须有存放它们的统一容器。为了解决这个问题,Netty提供了CompositeByteBuf。CompositeByteBuf 里面有个ComponentList,继承ArrayList,聚合的bytebuf都放在ComponentList里面,最小容量为16,当超过16时候,CompositeByteBuf是创建一个新的bytebuf,把数组里的16个bytebuf 写到这个新创建bytebuf里,然后把ComponentList清空掉,并把新创建的一个大的bytebuf添加到该ComponentList里,这时候就会涉及到多次copy。所以在使用的时候务必要设置好maxNumComponents,避免不必要的聚合。源码如下:
|
|
UnpooledHeapByteBuf 和UnpooledDirectByteBuf
首先看看它们的继承关系:UnpooledHeapByteBuf 和 UnPooledHeapByteBuf –> AbstractReferenceCountedByteBuf –> AbstractByteBuf;基本上的特性都来自于AbstractReferenceCountedByteBuf和AbstractByteBuf;AbstractByteBuf 都做了哪些事儿呢?我们先看一下其主要的成员变量:读写指针;用于标记回滚的 marked 读写指针;最大容量 maxCapacity,用于进行内存保护;与本 ByteBuf 大小端属性相反的 ByteBuf:SwappedByteBuf,除此之外还提供了操作索引:修改读写指针、mark & reset;重用缓冲区:discardReadBytes;丢弃部分数据:skipBytes等子类的通用功能;AbstractReferenceCountedByteBuf实现了计数相关的功能,我们看一下其成员变量:refCnt:记录对象引用次数;refCntUpdater:用于对 refCnt 进行原子更新。
UnpooledHeapByteBuf 是基于堆内存进行内存分配的字节缓冲区,它没有基于对象池实现,意味着每次 I/O 读写都会创建一个新的 UnpooledHeapByteBuf 对象,频繁进行内存的分配和释放对性能会有一定的影响,但是相对堆外内存的申请和释放,成本稍低。它的成员变量主要有负责内存分配的 ByteBufAllocator;缓冲区实现 byte 数组和从 ByteBuf 到 NIO 的 ByteBuffer 的转换对象 tmpNioBuf。
UnpooledDirectByteBuf是通过ByteBuffer.allocateDirect()方法来分配直接内存,并指向变量ByteBuffer。
PooledByteBuf
池化的好处在于能快速分配内存,同时复用对象,降低gc频率。PooledByteBuf有3个子类,分别是PooledDirectByteBuf,PooledHeapByteBuf,PooledUnsafeDirectByteBuf,主要关注其池化的原理,包括内存的设计和Recycler对象池的设计。
我们从PoolThreadCache入手,由下面的代码我们分析其内存设计
|
|
内存池的数据结构(arena、chunk、page、subpage)
netty里面,内存单元是以Chunk为单位的向操作系统申请的,一个内存单元16M;但是如果我们要分配10k的内存,用一个chunk就太浪费了。所以chunk下面又有page,一个page的大小8k,所以一个chunk一共有16m/8k=2^11个page。如果要找到10k的内存,只要找到两个page就可以;如果我们每次只要分配10b的内存,一个page又显得太浪费了,所以又开始有了subpage;
首先我们看arena,arena分为heapArena和directArena。
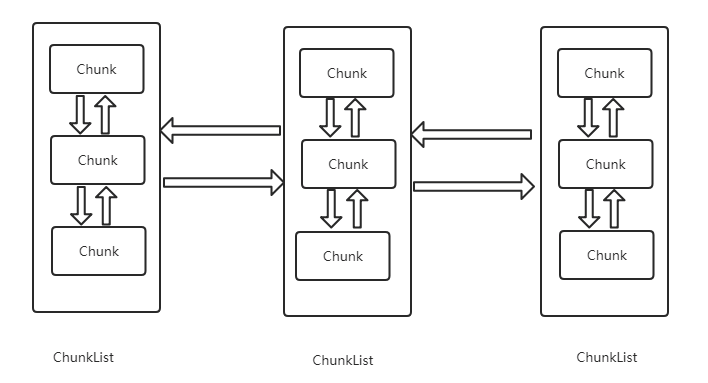
一个Arena由多个ChunkList组成,每个ChunkList之间通过双向链表的方式连接。一个ChunkList又由多个Chunk通过双向链表的方式组成。也就是各个Chunlist组成双向链表,ChunkList里面的Chunk又各自组成双向链表。
ChunList之间为什么要通过双向链表的方式连接?先给出答案:每个ChunkList里面的Chunk的使用率是不同的,Chunk使用率相同的归位一个ChunList,这样netty就能通过一定的算法找到合适的Chunk,提高内存分配的效率。
|
|
如果我们要分配的内存小于Chunk也就是16M,我们用chunk来分配不划算,浪费空间,所以就有了page。一个page的大小是8k,如果我们要分配内存是10k,那么我们用chunk里面的两个page来分配就很划算了。但是如果只要2k呢,一个page也显得不划算,所有又有了subpage。subpage的大小介于0~8k之间。我们看到PoolArena里面有个PoolSubpage,PoolSubpage有个elemSize,就是subpage的大小,可以为0~8k之间的值,有个bitmap,如果是1说明分配了,是0则未分配。
prev和next指针,说明subpage之间也就通过双向链表链接的,第一个成员变量final PoolChunk
|
|
缓存的数据结构
MemoryRegionCache就是其缓存的数据结构,它是个抽象类,有2个子类,分别是NormalMemoryRegionCache和SubPageMemoryRegionCache;
|
|
queue 里面的Entry有recyclerHandle和chunk两个属性,chunk就是内存,handler是指向内存的指针(指向唯一一块连续的内存),通过chunk和handler就可以找到唯一 一块内存;
sizeClass 大小有tiny(0~512B)、small(512B~8K)、normal(8K~16M),由于16M以上的数据不加入缓存,所以没有16M以上的大小;
size 如果是tiny的,有32个,每个的size是16B的倍数,也就是,tiny大小的MemoryRegionCache组合成一个长度为32的数组,分别有:0,16B,32B,48B,72B…496B。不包括512B。个数就是496/16+1=32;如果是small的,有4个,每个的size分别为512B,1K,2K,4K,也就是,small大小的MemoryRegionCache组合成一个长度为4的数组;如果是normal的,有3个,每个的size分别为8K,16K,32K,也就是normal大小的MemoryRegionCache组合成一个长度为3的数组,所以有32+4+3=39种内存规格的MemoryRegionCache。
缓存的分配
我们回到PoolArena的allocate来看看缓存分配的流程
|
|
我们以cache.allocateTiny(this, buf, reqCapacity, normCapacity)分配tiny的内存为例子,其他small或者normal的流程大致相同,流程如下:
|
|
找到对应size的MemoryRegionCache
|
|
从queue中弹出一个entry给ByteBuf初始化
|
|
将探出的entry扔到对象池里面复用。
netty为了减少对象的回收消耗的资源,专门做了一个对象池,不需要的对象可以回收,下次使用
|
|
内存的分配(page && subpage && huge)
我们继续看这个代码
|
|
page级别内存分配
|
|
ByteBuf的创建
官方的建议是通过ByteBufAllocator来创建,ByteBufAllocator是个接口,我们来看一下类的继承图:
同时又分为堆内和堆外,关于ByteBufAllocator,参考Netty之ByteBufAllocator。
ByteBuf的释放
UnpooledHeapByteBuf 和UnpooledDirectByteBuf
|
|
PooledHeapByteBuf和PooledDirectByteBuf
|
|
参考项目
https://github.com/Luckylau/Netty-Learn
参考
https://www.jianshu.com/p/5959aa4ab1a9
https://www.jianshu.com/p/bdd37e2750da
https://www.jianshu.com/p/854b855bd198