concurrentHashmap是Java工程师接触最多的关于并发和线程安全的类,本篇从jdk1.6, jdk1.7, jdk1.8三个版本的实现来详细分析其设计之美。
结构原型
首先简单从整体把握concurrentHashmap的结构原理。
JDK1.6和JDK1.7版本
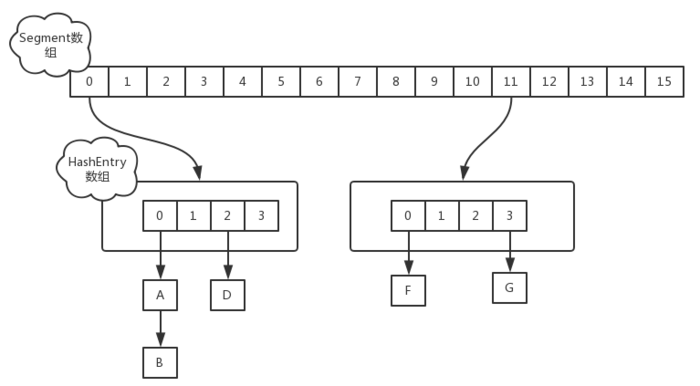
该版本的ConcurrentHashMap结构:每一个segment都是一个HashEntry
JDK1.8版本
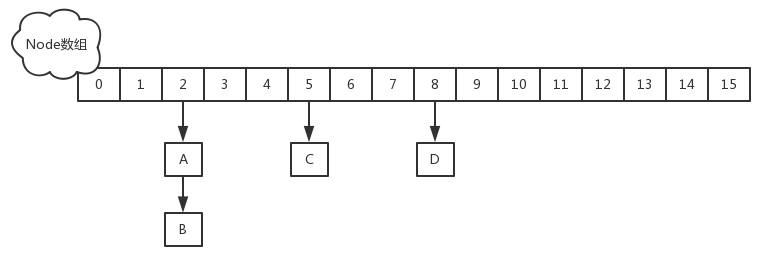
该版本的ConcurrentHashMap结构:放弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap。其中Node数组里面的元素包括TreeBin,ForwardingNode ,Node 。因为放弃了Segment,所以具体并发级别可以认为是hash桶是数量,也就是容量,会随扩容而改变,不再是固定值。
构造函数
名词解释
initialCapacity:初始化容量,指的是所有Segment中的hash桶的数量和,默认16。
concurrencyLevel:最大并发级别,也是数组segments的最大长度,初始化之后就不会改变,实际扩容的是每个segment里的hash桶,默认16。
loadFactor:每个Segment的加载因子,当个数大于threshold=hash桶数量*loadFactor时候会扩容。
Unsafe:这是jdk1.7,1.8常用的机制,可以看这篇文章。
|
|
sizeCtl: java1.8版本特有的,用于数组的初始化与扩容控制;当sizeCtl = -1 时,表明table正在初始化;当sizeCtl = 0时,表明用了无参构造方法,没有指定初始容量默认值;当sizeCtl > 0时,表明用了传参构造方法,指定了初始化容量值;当sizeCtl = -(1+ N),表明在扩容, 其中N的低RESIZE_STAMP_SHIFT位表示参与扩容线程数。
JDK1.6版本
|
|
JDK1.7版本
|
|
JDK1.8版本
|
|
基本类
HashEntry和Segments
JDK1.6版本
|
|
|
|
附录:
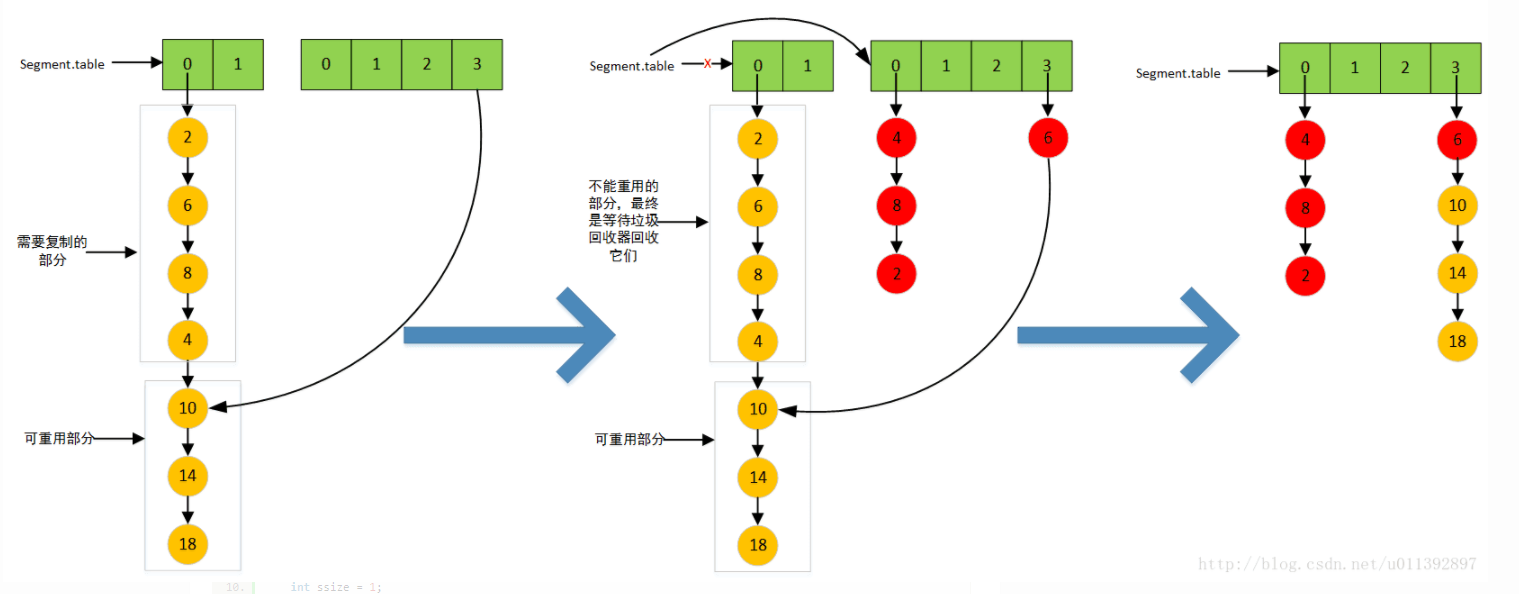
jdk1.6的扩容图。我们假设原先某个segment的table大小为2,扩容后的newtable大小为4,table[0]对应一个大小为7的HashEntry,经过e.hash & sizeMask之后,10-14-18是落到newtable[3],6也是落到newtable[3],,2-8-4是落到newtable[0]。这个扩容的过程是这样的:首先rehash过程会找到可重用部分,即图上的10-14-18,通过newTable[lastIdx] = lastRun整体的将它们放到newtable[3]的位置去,各个元素的顺序相对原来并没有变化的;对于不可重用的部分,只有遍历和复制的方式,通过头插法,放到newtable中,这时我们发现6被头插到newtable[3]中,所以newtable[3]中的链表元素顺序为6-10-14-18,2-8-4被头插到newtable[0]中,顺序变为倒序了。这些操作完成之后才table = newTable,这是为了保证其他线程能够继续执行读操作,不执行手动将原来table赋值为null,只是再最后修改一次table的引用;对于原先的table,会被gc回收掉。
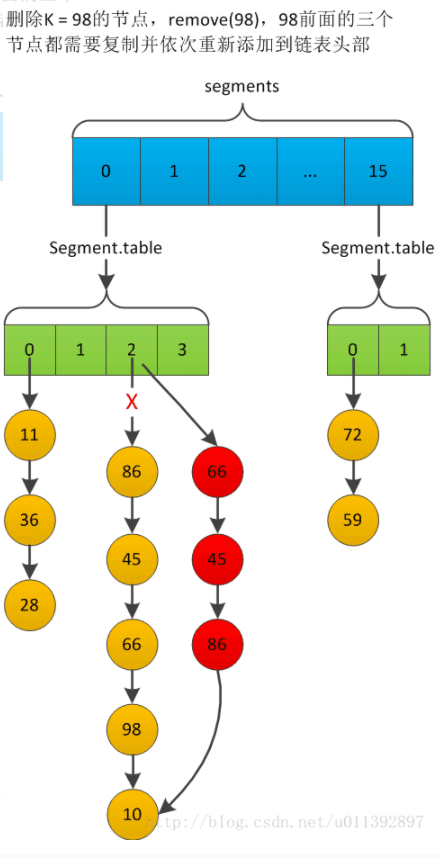
jdk1.6的删除图。假设我们从segment[0].table[2]中删除98的节点。
JDK1.7版本
|
|
|
|
JDK1.8版本
|
|
常用方法
读方法,外面封装一层其实还是操作segment。
JDK1.6版本
|
|
写方法
|
|
JDK1.7版本
读方法
|
|
写方法
|
|
JDK1.8版本
读方法
|
|
读方法
|
|
参考:
https://blog.csdn.net/fenglibing/article/details/17119959
https://blog.csdn.net/u011392897/article/details/60466665
https://blog.csdn.net/u011392897/article/details/60469263
https://blog.csdn.net/u011392897/article/details/60479937