网络
网络(network)是一个隔离的二层网段,类似于物理网络世界中的虚拟 LAN (VLAN)。更具体来讲,它是为创建它的租户而保留的一个广播域,或者被显式配置为共享网段。端口和子网始终被分配给某个特定的网络。根据网络的类型,Neutron network 可以分为:
VLAN network(虚拟局域网) :基于物理 VLAN 网络实现的虚拟网络。共享同一个物理网络的多个 VLAN 网络是相互隔离的,甚至可以使用重叠的 IP 地址空间。每个支持 VLAN network 的物理网络可以被视为一个分离的 VLAN trunk,它使用一组独占的 VLAN ID。有效的 VLAN ID 范围是 1 到 4094。
Flat network:基于不使用 VLAN 的物理网络实现的虚拟网络。每个物理网络最多只能实现一个虚拟网络。
local network(本地网络):一个只允许在本服务器内通信的虚拟网络,不知道跨服务器的通信。主要用于单节点上测试。
GRE network (通用路由封装网络):一个使用 GRE 封装网络包的虚拟网络。GRE 封装的数据包基于 IP 路由表来进行路由,因此 GRE network 不和具体的物理网络绑定。
VXLAN network(虚拟可扩展网络):基于 VXLAN 实现的虚拟网络。同 GRE network 一样, VXLAN network 中 IP 包的路由也基于 IP 路由表,也不和具体的物理网络绑定。
关系:
(1)tenant —- 1:n —– network ——- 1:n ——- subnet (一个 tenant 可以拥有多个 network,一个 network 可以包含多个 subnet)
(2)network ——- 1: n ——- port —— 1:1 — subnet(一个network 可以有多个 port, 每个 port 连接一个 subnet)(若创建虚机时指定的是 net-id,那么虚机将随机地从该 network 包含的 subnet 中分配 IP)
(3)VM —– 1 : n —- NIC —– 1:1 — port(一个 VM 可以有多个 NIC,每个 NIC 连接一个 port)(可以在创建虚机时指定一个或者多个 port)
(4)Tenant —– 1 : n —- Router —– 1 : n —— subnet/ext-network (一个 tenant 可以拥有多个 router,每个 router 在 Neutron network 节点上使用一个 Linux network namespace,其 ID 就是 neutron router-list 得到的 router 的 ID; 一个 router 连接一个通向外网的 gateway 和多个该 tenant 的 subnet)
(5)network —- 1 : 1 —- Dnamasq —– 1: n —– subnet (一个 network 有一个 Dnsmasq 进程,该进程为多个启动了 DHCP 的 subnet 服务,分配它们拥有的 IP 给虚机)
Neutron 管理的实体如下:
网络: 隔离的 L2 域,可以是虚拟、逻辑或交换,同一个网络中的主机彼此 L2 可见。
子网: IP 地址块,其中每个虚拟机有一个 IP,同一个子网的主机彼此 L3 可见。
端口: 网络上虚拟、逻辑或交换端口。
Linux相关技术
Neutron 的设计目标是实现“网络即服务”,为了达到这一目标,在设计上遵循了基于“软件定义网络”实现网络虚拟化的原则,在实现上充分利用了 Linux 系统上的各种网络相关的技术。
理解了 Linux 系统上的这些概念将有利于快速理解 Neutron 的原理和实现。
涉及的 Linux 网络技术
bridge:网桥,Linux中用于表示一个能连接不同网络设备的虚拟设备,linux中传统实现的网桥类似一个hub设备,而ovs管理的网桥一般类似交换机。
br-int:bridge-integration,综合网桥,常用于表示实现主要内部网络功能的网桥。
br-ex:bridge-external,外部网桥,通常表示负责跟外部网络通信的网桥。
GRE:General Routing Encapsulation,一种通过封装来实现隧道的方式。在openstack中一般是基于L3的gre,即original pkt/GRE/IP/Ethernet
VETH:虚拟ethernet接口,通常以pair的方式出现,一端发出的网包,会被另一端接收,可以形成两个网桥之间的通道。
qvb:neutron veth, Linux Bridge-side
qvo:neutron veth, OVS-side
TAP设备:模拟一个二层的网络设备,可以接受和发送二层网包。
TUN设备:模拟一个三层的网络设备,可以接受和发送三层网包。
iptables:Linux 上常见的实现安全策略的防火墙软件。
Vlan:虚拟 Lan,同一个物理 Lan 下用标签实现隔离,可用标号为1-4094。
VXLAN:一套利用 UDP 协议作为底层传输协议的 Overlay 实现。一般认为作为 VLan 技术的延伸或替代者。
namespace:用来实现隔离的一套机制,不同 namespace 中的资源之间彼此不可见。
GRE网络, Vlan网络, Vxlan网络
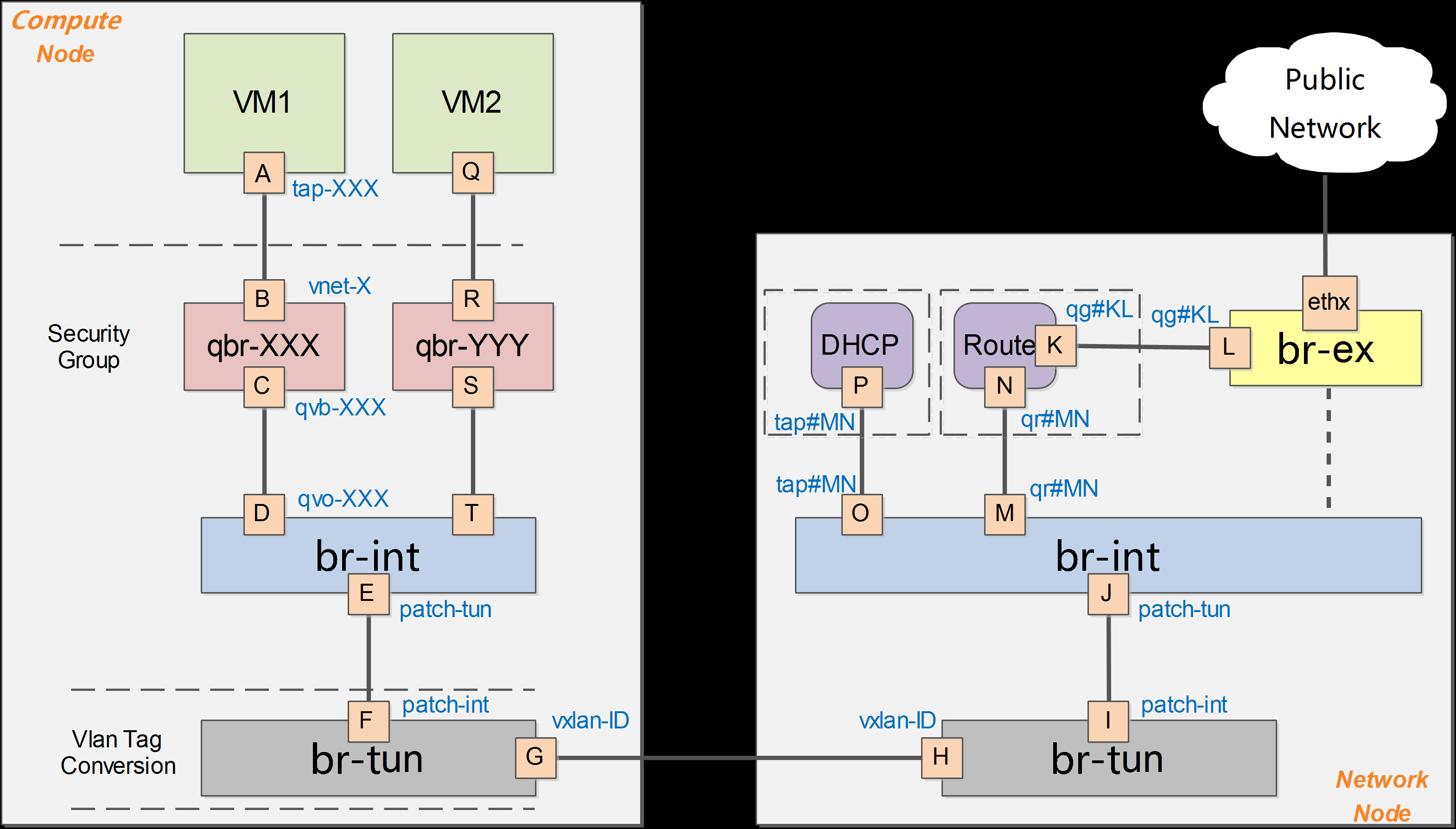
举例GRE网络
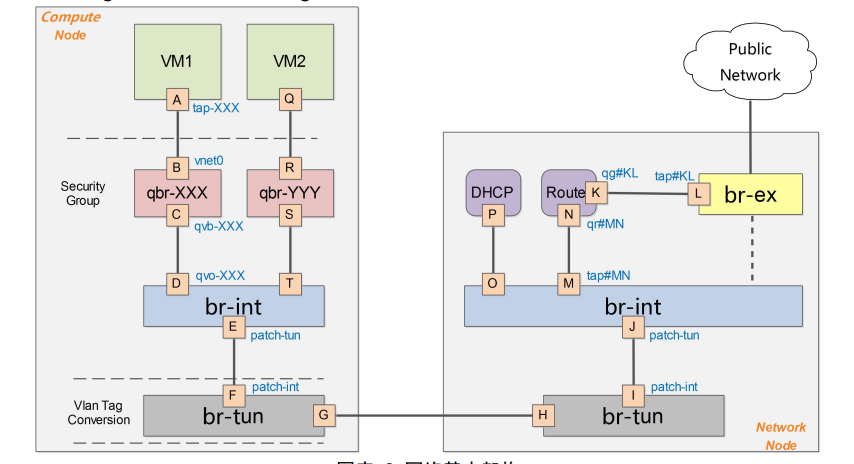
在 VM1 中,虚拟机的网卡实际上连接到了物理机的一个 TAP 设备(即 A,常见名称如 tap-XXX)上,A 则进一步通过 VETH pair(A-B)连接到网桥 qbr-XXX 的端口 vnet0(端口 B)上,之后再通过 VETH pair(C-D)连到 br-int 网桥上。一般 C 的名字格式为 qvb-XXX,而 D的名字格式为 qvo-XXX。注意它们的名称除了前缀外,后面的 id 都是一样的,表示位于同一个虚拟机网络到物理机网络的连接上。
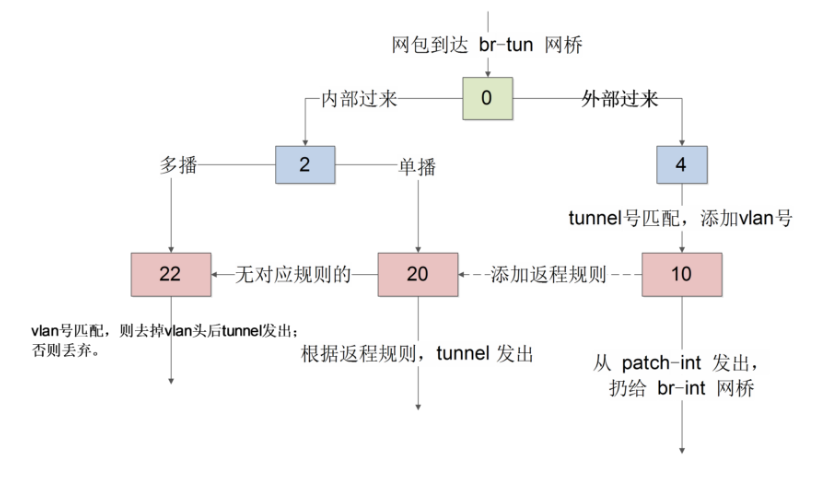
br-tun转发逻辑:
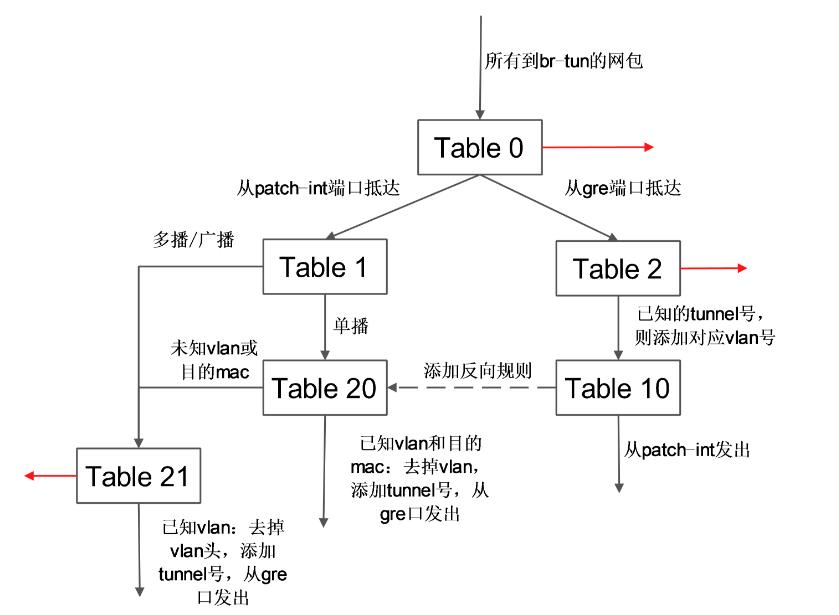
表 10 负责学习。有一条规则,基于 learn 行动来创建反向(内部网包从 gre 端口发出去)的规则。如下所示:

learn 行动并非标准的 openflow 行动,是 openvswitch 自身的扩展行动,这个行动可以根据流内容动态来修改流表内容。这条规则首先创建了一条新的流(该流对应 vm 从 br-tun 的 gre 端口发出的规则):
其中 table=20 表示规则添加在表 20;
NXM_OF_VLAN_TCI[0..11] 表示匹配包自带的vlan id;
NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[] 表示 L2 目标地址需要匹配当前包的 L2 源地址;
load:0->NXM_OF_VLAN_TCI[],去掉vlan;
load:NXM_NX_TUN_ID[]->NXM_NX_TUN_ID[],添加 tunnel 号为原始 tunnel 号;
output:NXM_OF_IN_PORT[],发出端口为原始包抵达的端口。
向表 20 添加完规则后,最后将匹配的当前网包从端口 1(即 patch-int)发出。
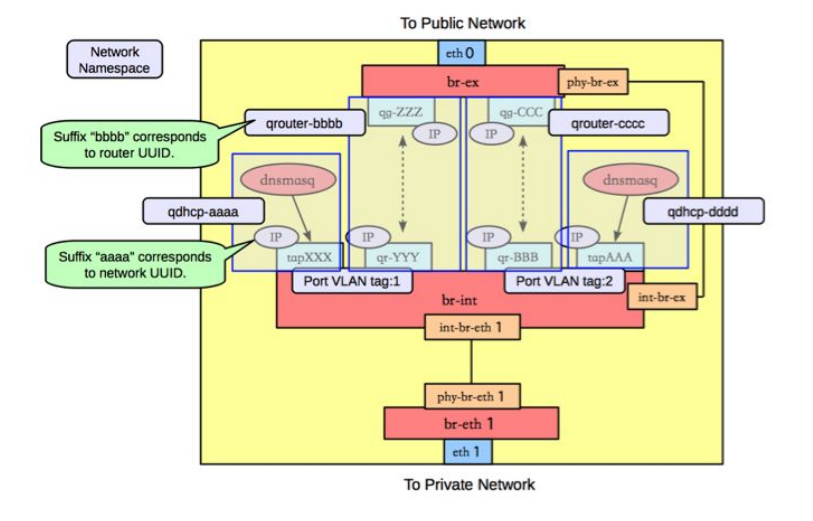
举例VLAN网络:
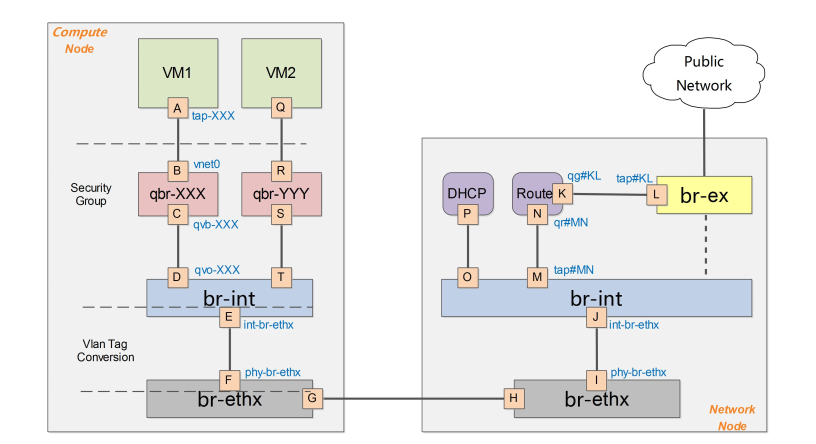
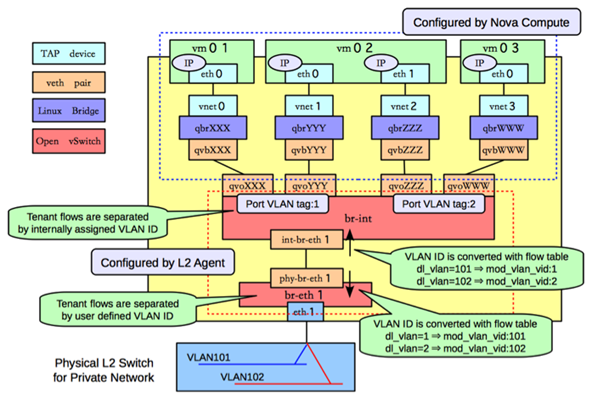
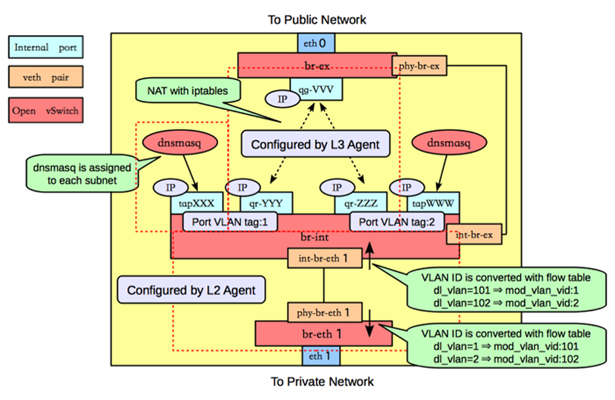
路由是L3 agent来实现,每个子网在br-int上有一个端口(qr-YYY和qr-ZZZ,已配置IP,分别是各自内部子网的网关),L3 agent绑定到上面。要访问外部的公共网络,需要通过L3 agent发出,而不是经过int-br-ex到phy-br-ex(实际上并没有网包从这个veth pair传输)。如果要使用外部可见的floating IP,L3 agent仍然需要通过iptables来进行NAT。
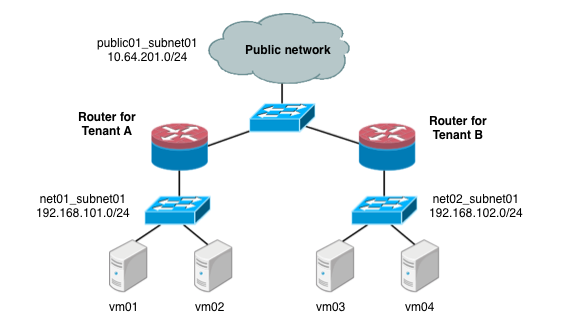
在多租户情况下
举例VXLAN网络:(详细分析)
当我们部署环境之后(一个网络节点和两个计算节点)我们查看计算机节点的状态如下,此时并没有vxlan隧道的建立。我们同时发现当创建完成网络和子网的时候(创建了7.7.7.0/24子网),依然没有vxlan隧道。
|
|
只有当有虚拟机接入该子网时候,我们发现虚拟机所在的计算节点会和网络节点建立vxlan隧道。
|
|
我们查看br-tun的流表如下(开启了l2 population) :
当数据包由in_port = 1(也就是由br-int发出)到达table 0时候,会转给table 2;如果是arp广播请求,因为开启l2 population,也就是arp_responder之后,会提交给 table 21。此时table21有条规则会处理这个请求,这条规则专门由l2 population发来的 entry 来更新 。
table 21 的更新过程并非网上所讲的那么简单,实际过程如下:假如我们创建了网络A和网络B ,有2个计算机点和1个网络节点。创建一台虚拟机aa加入网络A,同时落地在计算节点1时候,本计算节点的table21只有dhcp的arp的回应记录。再创建一虚拟机bb加入网络B,同时落地在计算节点2时候,本计算节点的table21只有dhcp的arp的回应记录,计算节点1的table21并没有bb的arp的回应记录。创建第三台虚拟机加入网络A,如果落地在计算节点1时候,两个计算节点的table21没有任何更新。当创建第四台虚拟机加入网络A,同时落地在计算机点2时候,计算机点2的table 21更新了所有在计算节点1的同一网络的虚拟机的arp信息,同时table 20记录了所有到达计算机点1同一网络的虚拟机的规则。计算节点1的table21也更新了计算节点2的同网络的虚拟机的arp回应,table20也记录了到达其的规则。
br.add_flow(table=21, priority=1, proto=’arp’, dl_vlan=local_vid, nw_dst= ip, actions=actions) 其中action为:
|
|
如果table21还是无法解决arp的问题就发给table22 去 flood 到所有端口。如果不是arp请求就转到table 20 ,通过已知学习到的mac地址从相应的口发出,如果不能处理也是发给table 22去flood到所有的端口。
当数据包从in_port=4(也就是由发往br-int)到达table 0时候,会提交给table 4, 它根据tunel号修改为内部vlan号,然后提交给table 10 ,它进行学习更新table 20,然后从patch-int发出。
table 10使用了 openvswitch 的 learn 动作。该动作能根据处理的流来动态修改其它表中的规则。因为此时访问虚拟机的只有dhcp服务,我们看到table 20有一条到达dhcp的流表,这个流表就是这个learn动作生成的。
table=20 说明是修改表 20 中的规则,后面是添加的规则内容;
NXM_OF_VLAN_TCI[0..11],匹配跟当前流同样的 VLAN 头,其中 NXM 是 Nicira Extensible Match 的缩写 ,dl_vlan=3;
NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[],将 mac source address 记录,所以结果中有 dl_dst= fa:16:3e:c0:0e:07;
load:0->NXM_OF_VLAN_TCI[],在发送出去的时候,vlan tag设为0,所以结果中有 actions=strip_vlan;
load:NXM_NX_TUN_ID[]->NXM_NX_TUN_ID[],发出去的时候,设置 tunnul id,所以结果中有set_tunnel: 0x8;
output:NXM_OF_IN_PORT[],指定发送给哪个port,由于是从 port 4进来的,因而结果中有output4。
|
|
下图是没有开启l2popluation功能,从上述流表看出与开启l2popluation功能不同。
L2 Population
L2 Population 是用来提高 VXLAN 网络 Scalability 的,减少广播风暴。
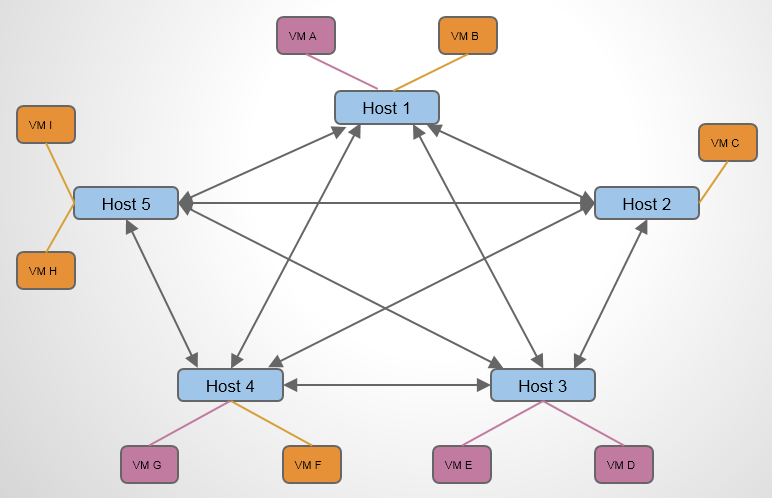
这是一个包含 5 个节点的 VXLAN 网络,每个节点上运行了若干 VM。现在假设 Host 1 上的 VM A 想与 Host 4 上的 VM G 通信,VM A 要做的第一步是获知 VM G 的 MAC 地址。 于是 VM A 需要在整个 VXLAN 网络中广播 APR 报文:“VM G 的 MAC 地址是多少?” 如果没有L2poluation,情况会如下:
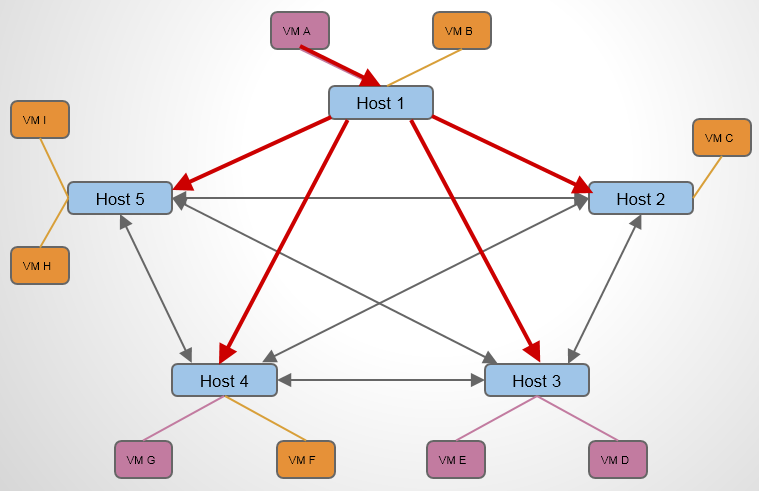
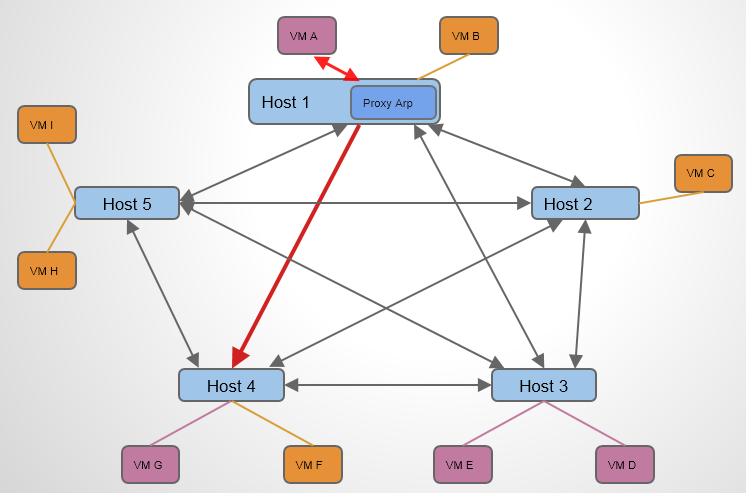
L2 Population 的作用是在 VTEP 上提供 Porxy ARP 功能,使得 VTEP 能够预先获知 VXLAN 网络中,包括VM IP – MAC 对应关系和 VM – VTEP 的对应关系。当 Host 1 上的 同网段的VM A 想与 Host 4 上的同网段的 VM G 通信时,Host 1 上的 VTEP 直接响应 VM A 的 APR 请求即可(为什么HOST1 上会响应,参看上文),告诉VM G的MAC地址。当Host 1 上的VMA想与不同网段的VM G 通信时,首先Host 1 上的 VTEP 响应 VMA所在网络的网关的arp信息(当路由器创建并关联网络时候,L2 Population会使得该网络所跨的所有HOST的VTEP更新该路由器的arp回应信息和如何到达的该路由器的流表,说具体就是table21和table20的更新),数据包会发送给路由器,到达路由器之后,如果路由器同时关联着VM G 所在的网络,它就会发送arp广播请求VM G 的mac,此时网络节点的table21会响应(L2 Population的功能)VM G的信息,路由器知道了VM G的mac地址后,发送单播,由table0到table2,再由table20匹配相关流表,tunnel发出。数据包到达VM G所在的HOST之后,首先匹配table0,然后转给table4,table4去tunnel转给table10, table10 学习完存到table 20之后从patch-int口仍给br-int。br-int相当于一个普通的交换机,将数据包转发给VM G。
另外我还发现如果开启了l2population之后,table10的学习可以去掉。
|
|