Python垃圾回收机制
Python GC主要使用引用计数(reference counting)来跟踪和回收垃圾。在引用计数的基础上,通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用问题,通过“分代回收”(generation collection)以空间换时间的方法提高垃圾回收效率。简单来说就是以引用计数为主,标记-清除和分代收集两种机制为辅
引用计数机制
引用计数是啥?
python里每一个东西都是对象,它们的核心就是一个结构体:PyObject
|
|
PyObject是每个对象必有的内容,其中ob_refcnt就是做为引用计数。当一个对象有新的引用时,它的ob_refcnt就会增加,当引用它的对象被删除,它的ob_refcnt就会减少
|
|
当引用计数为0时,该对象生命就结束了。
导致引用计数+1的情况
对象被创建,例如a=23
对象被引用,例如b=a
对象被作为参数,传入到一个函数中,例如func(a)
对象作为一个元素,存储在容器中,例如list1=[a,a]
导致引用计数-1的情况
对象的别名被显式销毁,例如del a
对象的别名被赋予新的对象,例如a=24
一个对象离开它的作用域,例如f函数执行完毕时,func函数中的局部变量
对象所在的容器被销毁,或从容器中删除对象
|
|
引用计数机制的优点:
1、简单
2、实时性:一旦没有引用,内存就直接释放了。不用像其他机制等到特定时机。实时性还带来一个好处:处理回收内存的时间分摊到了平时。
引用计数机制的缺点:
1、维护引用计数消耗资源
2、循环引用
循环引用如何内存泄漏?
有 del() 函数的对象间的循环引用是导致内存泄漏的主凶。但没有del()函数的对象间的循环引用是可以被垃圾回收器回收掉的。
首先我们要看一下没有内存泄漏的例子:
|
|
我们通过自我引用引起内存泄露,在上述程序中将 make_cycle_ref()添加如下:
|
|
我们互相引用导致内存泄漏,代码如下:
|
|
注意:如果我们将class cycleLeak(object)的__del__属性删除,garbage object num将会是0,为什么呢?因为如果循环引用中,两个对象都定义了__del__方法,gc模块不会销毁这些不可达对象,因为gc模块不知道应该先调用哪个对象的__del__方法,所以为了安全起见,gc模块会把对象放到gc.garbage中,但是不会销毁对象。
上述的例子使用了gc模块,我们简单的介绍一下gc模块
常用函数:
gc.set_debug(flags) 设置gc的debug日志,一般设置为gc.DEBUG_LEAK ,也可以是上述事例
gc.collect([generation]) 显式进行垃圾回收,可以输入参数,0代表只检查第一代的对象,1代表检查一,二代的对象,2代表检查一,二,三代的对象,如果不传参数,执行一个full collection,也就是等于传2。返回不可达(unreachable objects)对象的数目
gc.get_count() 获取当前自动执行垃圾回收的计数器,返回一个长度为3的列表
解释如下:
|
|
(581,8,0)其中
581指距离上一次一代垃圾检查Python分配内存的数目减去释放内存的数目
8指距离上一次二代垃圾检查,一代垃圾检查的次数
0是指距离上一次三代垃圾检查,二代垃圾检查的次数
gc.set_threshold(threshold0[, threshold1[, threshold2]) 设置自动执行垃圾回收的频率。
解释如下:
gc模快有一个自动垃圾回收的阀值,即通过gc.get_threshold函数获取到的长度为3的元组,例如(700,10,10)每一次计数器的增加,gc模块就会检查增加后的计数是否达到阀值的数目,如果是,就会执行对应的代数的垃圾检查,然后重置计数器。
例如,假设阀值是(700,10,10):
- 当计数器从
(699,3,0)增加到(700,3,0),gc模块就会执行gc.collect(0),即检查一代对象的垃圾,并重置计数器为(0,4,0) - 当计数器从
(699,9,0)增加到(700,9,0),gc模块就会执行gc.collect(1),即检查一、二代对象的垃圾,并重置计数器为(0,0,1) - 当计数器从
(699,9,9)增加到(700,9,9),gc模块就会执行gc.collect(2),即检查一、二、三代对象的垃圾,并重置计数器为(0,0,0)
使用方法:
必须要import gc模块,并且is_enable()=True才会启动自动垃圾回收。
这个机制的主要作用就是发现并处理不可达的垃圾对象。
垃圾回收=垃圾检查+垃圾回收
在Python中,采用分代收集的方法。把对象分为三代,一开始,对象在创建的时候,放在一代中,如果在一次一代的垃圾检查中,改对象存活下来,就会被放到二代中,同理在一次二代的垃圾检查中,该对象存活下来,就会被放到三代中。
标记-清除?
标记-清除机制,顾名思义,首先标记对象(垃圾检测),然后清除垃圾(垃圾回收)。基本思路是先按需分配,等到没有空闲内存的时候从寄存器和程序栈上的引用出发,遍历以对象为节点、以引用为边构成的图,把所有可以访问到的对象打上标记,然后清扫一遍内存空间,把所有没标记的对象释放。
首先初始所有对象标记为白色,并确定根节点对象(这些对象是不会被删除),标记它们为黑色(表示对象有效)。将有效对象引用的对象标记为灰色(表示对象可达,但它们所引用的对象还没检查),检查完灰色对象引用的对象后,将灰色标记为黑色。重复直到不存在灰色节点为止。最后白色结点都是需要清除的对象。
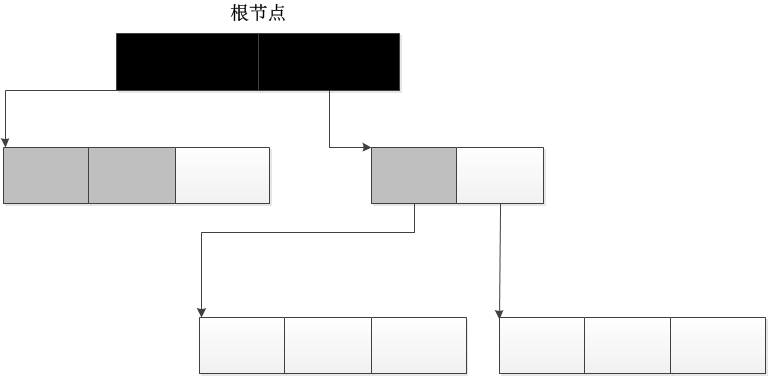
这里所采用的高级机制作为引用计数的辅助机制,用于解决产生的循环引用问题。而循环引用只会出现在“内部存在可以对其他对象引用的对象”,比如:list,class等。为了要将这些回收对象组织起来,需要建立一个链表。自然,每个被收集的对象内就需要多提供一些信息,下面代码是回收对象里必然出现的。
|
|
一个对象的实际结构如图所示:

通过PyGC_Head的指针将每个回收对象连接起来,形成了一个链表,也就是在1里提到的初始化的所有对象。
分代收集?
分代技术是一种典型的以空间换时间的技术,这也正是java里的关键技术。这种思想简单点说就是:对象存在时间越长,越可能不是垃圾,应该越少去收集。分代回收的整体思想是:将系统中的所有内存块根据其存活时间划分为不同的集合,每个集合就成为一个“代”,垃圾收集频率随着“代”的存活时间的增大而减小,存活时间通常利用经过几次垃圾回收来度量。
Python默认定义了三代对象集合,索引数越大,对象存活时间越长。
举例: 当某些内存块M经过了3次垃圾收集的清洗之后还存活时,我们就将内存块M划到一个集合A中去,而新分配的内存都划分到集合B中去。当垃圾收集开始工作时,大多数情况都只对集合B进行垃圾回收,而对集合A进行垃圾回收要隔相当长一段时间后才进行,这就使得垃圾收集机制需要处理的内存少了,效率自然就提高了。在这个过程中,集合B中的某些内存块由于存活时间长而会被转移到集合A中,当然,集合A中实际上也存在一些垃圾,这些垃圾的回收会因为这种分代的机制而被延迟。
这样的思想,可以减少标记-清除机制所带来的额外操作。分代就是将回收对象分成数个代,每个代就是一个链表(集合),代进行标记-清除的时间与代内对象存活时间成正比例关系。
|
|
从上面代码可以看出python里一共有三代,每个代的threshold值表示该代最多容纳对象的个数。默认情况下,当0代超过700,或1,2代超过10,垃圾回收机制将触发。0代触发将清理所有三代,1代触发会清理1,2代,2代触发后只会清理自己。
整个过程包括链表建立,确定根节点,垃圾标记,垃圾回收。
链表建立
0代触发将清理所有三代,1代触发会清理1,2代,2代触发后只会清理自己。在清理0代时,会将三个链表(代)链接起来,清理1代的时,会链接1,2两代。在后面三步,都是针对的这个建立之后的链表。
确定根节点
如下图的例子,ist1与list2循环引用,list3与list4循环引用,a是一个外部引用。
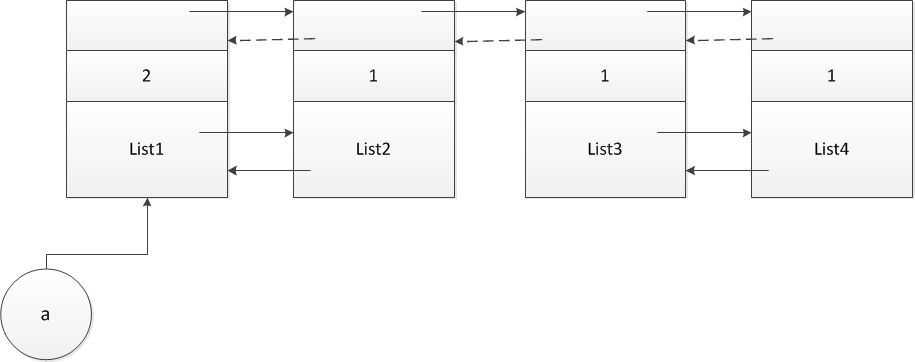
对于这样一个链表,我们如何得出根节点呢。python里是在引用计数的基础上又提出一个有效引用计数的概念。顾名思义,有效引用计数就是去除循环引用后的计数。下面是计算有效引用计数的相关代码:
|
|
update_refs函数里建立了一个引用的副本。
visit_decref函数对引用的副本减1,subtract_refs函数里traverse的作用是遍历对象里的每一个引用,执行visit_decref操作。
最后,链表内引用计数副本非0的对象,就是根节点了。
垃圾标记
接下来,python建立两条链表,一条存放根节点,以及根节点的引用对象。另外一条存放unreachable对象。
代码如下:
|
|
标记之后,链表如下图:

垃圾回收
回收的过程,就是销毁不可达链表内对象。下面代码就是list的清除方法:
|
|
参考:
http://www.cnblogs.com/hackerl/p/5901553.html
http://www.jianshu.com/p/1e375fb40506